 Reguläre Sprache - Pumping Lemma Reguläre Sprache - Pumping Lemma |
Laura94
unregistriert
 |
|
| Reguläre Sprache - Pumping Lemma |
     |
Meine Frage:
Hey, ich beschäftige mich grade mit dem Pumping-Lemma, muss aber gestehen, dass es mir ziemlich schwer fällt, es zu verstehen.
Reguläre Sprachen wurden bei uns in der Vorlesung über die Chomsky-Hierarchie definiert, also:
Typ 3 ("regulär")
Für alle Regeln w1 -> w2 gilt:
w1 ist eine einzelne Variable (![[latex]w1 \in V[/latex]](http://www.matheboard.de/latex2png/latex2png.php?w1 \in V) ) )
![[latex]w2 \in E \bigcup EV[/latex]](http://www.matheboard.de/latex2png/latex2png.php?w2 \in E \bigcup EV) (rechte Seite ist einzelnes Terminalzeichen oder ein Terminalzeichen gefolgt von einer Variablen. (rechte Seite ist einzelnes Terminalzeichen oder ein Terminalzeichen gefolgt von einer Variablen.
Meine Ideen:
Wenn ich dann also ein Grammatik hätte zB:
G = ({S}, {a}, P, S)
mit P={
S->a
}
Dann entspräche das meinem Verständnis nach einer Grammatik für eine Typ3-Sprache, also einer regulären Sprache.
Eben die Sprache, die als Wort nur das a enthält.
Wenn ich letzte eine Zerlegung nach dem Pumping-Lemma suche, dann gibt es ja nur eine mögliche Zerlegung für:
x=uvw. Nämlich v=a mit n=1.
Demnach müsste ich das v ja jetzt aufpumpem können, und das Wort müsste immer noch in der Sprache liegen.
Für alle i aus der natürlichen Zahlen mit 0, gilt das das "aufgepumpte Wort" für i=0 und für alle i>=2 kein Wort der Sprache ist.
Somit müsste die Sprache ja nicht regulär sein.
Also irgendwo muss da ja ein Denkfehler drin sein, da die Sprache ja laut Definition eine reguläre Sprache sein sollte.
Hoffe jemand kann mir da weiterhelfen.
Grüße
|
|
 27.01.2015 20:47
27.01.2015 20:47 |
|
|
Karlito 
Kaiser

Dabei seit: 11.04.2011
Beiträge: 1.461
|
|
Genau das Problem hatte ich auch immer und habe es immer ignoriert. Ich werde mal versuche es zeitnah herauszufinden und hier zu posten.
Gruß,
Karlito
|
|
|
28.01.2015 00:33 |




|
|
Lena95
unregistriert
|
|
Vielen Dank 
|
|
|
28.01.2015 13:15 |
|
|
Laura94
Grünschnabel

Dabei seit: 28.01.2015
Beiträge: 6
|
|
| Zitat: |
Original von Lena95
Vielen Dank
|
Ups, obige Antwort kommt natürlich von mir, ich hatte versucht mich mit einem Matheboard Account anzumelden, da ich dachte die Foren würden vllt irgendwie "zusammenhängen".
Jetzt sollte ich richtig registriert sein
|
|
|
28.01.2015 13:20 |
|
|
Karlito
Kaiser
Dabei seit: 11.04.2011
Beiträge: 1.461
|
|
Ich habe jetzt schon mit 2 Studenten und einem Lehrstuhlmitarbeiter diskutiert. Bisher kein 100%iger Konsens. Meine Vermutung ist, dass man das n für die Mindestlänge einfach größer setzt als das längste Wort. Dann gibt es keine Wörter, welche länger sind als n und somit ist auch die Zerlegung hinfällig. Das wird so nicht aus der Formulierung klar, aber ich sehe als einzige logische Argumentation.
Ich frage bei Gelegenheit noch eine Bekannte, welche bei den Theoretikern arbeitet um das abzusichern.
Gruß,
Karlito
|
|
|
28.01.2015 13:48 |
|
|
Karlito
Kaiser
Dabei seit: 11.04.2011
Beiträge: 1.461
|
|
Auf jeden Fall ist es so, dass jede Sprache, welche nur endlich viele Elemente hat, regulär ist. Wie Du schon sagst, braucht man ja nur jedes Wort mit | in einem regulären Ausdruck zu verbinden. Somit gibt es einen regulären Ausdruck, welcher die Sprache akzeptiert und das genügt meist als Nachweis, dass die Sprache regulär ist. Alternativ kann man auch für jedes Wort einen endlichen Automaten konstruieren. Somit ist bewiesen, dass jedes Wort regulär ist. Die gesamte Sprache ist dann die Vereinigung aller dieser Wörter. Dazu konstruiert man einen neuen Automaten, indem man einen neuen Startzustand einführt und einen epsilon-Übergang zu den Startzuständen der Automaten der einzelnen Wörter.
Mir gefällt die Formulierung des Pumping Lemmas jedoch nicht, da es intuitiv erst einmal keine Aussage darüber gibt, wie das n zu gestalten ist. Das würde ich gern noch einmal hinterfragen. Ich denke, dass die Formulierung schon logisch durchdacht ist, aber ein quäntchen Verständnis fehlt. Die Theoretiker sind da sicher ein wenig fitter... Diejenigen, die ich bisher gefragt habe, waren durchweg eher Softwaretechnologen.
Gruß,
Karlito
|
|
|
28.01.2015 15:09 |
|
|
3c7
Grünschnabel
Dabei seit: 01.02.2015
Beiträge: 4
|
|
Hallo zusammen,
hab gerade ein ähnliches Problem. Eine meiner Meinung nach reguläre Sprache L = {(a^k)^2 | k>=0} lässt sich mit Hilfe einer Typ 3 Grammatik G=({a}, {S,A} {S->e | aA, A-> aS}, S) erstellen. Beispiele für in L enthaltene Wörter wären also L = {e, aa, aaaa, aaaaaa, ...}.
Wende ich nun das Pumping Lemma auf L an, komme ich schlussendlich auf einen Widerspruch.
Ich habe mal versucht, mein Vorgehen aufzuschreiben:
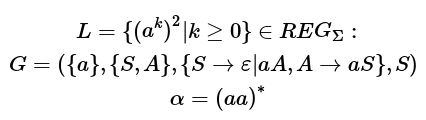

Ich vermute, der Fehler liegt in der Schlussfolgerung, beziehe mich ja nur auf die Länge des Wortes. Kann mir da jemand helfen?
Viele Grüße
Edit:
Andere Überlegung. Nach dem Pumping Lemma liegt die Länge von x zwischen zwei Quadraten und daher gehört x nicht in die Sprache:
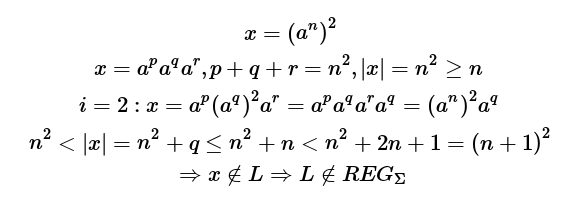
Andere Argumentation, gleiches Ergebnis. Da ist doch irgendwo ein gewaltiger Denkfehler drin...
Edit 2:
Zur Ursprungsthematik:
Ich gehe davon aus, das bei Sprachen mit endlicher Anzahl Wörter das Pumping Lemma nicht anwendbar ist. Wir haben bei uns in der Hochschule darüber gesprochen, dass die Variable für die Länge des gewählten Wortes - in diesem Fall n - quasi "unbekannt" ist. Man sagt nur, dass ![[latex]\exists n \in \mathbb N[/latex]](http://www.matheboard.de/latex2png/latex2png.php?\exists n \in \mathbb N) und ab der Länge des Wortes und ab der Länge des Wortes ![[latex]|x| \ge n[/latex]](http://www.matheboard.de/latex2png/latex2png.php?|x| \ge n) eine Zerlegung eine Zerlegung ![[latex]x=uvw[/latex]](http://www.matheboard.de/latex2png/latex2png.php?x=uvw) existiert. existiert.
Dieser Beitrag wurde 7 mal editiert, zum letzten Mal von 3c7: 01.02.2015 15:53.
|
|
|
01.02.2015 13:36 |
|
|
Laura94
Grünschnabel
Dabei seit: 28.01.2015
Beiträge: 6
|
|
Hey interessanter Beitrag, leider komme ich mit dem Pumping-Lemma allgemein garnicht klar.
Habe heut meine Klausur geschrieben und man sollte zeigen, dass folgende Sprache nicht regulär ist:
L={ a^s b^u | s > u}
Wenn ich jetzt n=u setze, dann ist jedes Wort x länger als 2*n. Da |uv|<n sein muss, kann v also nur aus a's bestehen. Wenn ich das Wort dann aufpumpe ist uv^iw immer noch in der Sprache, weil ich ja nur mehr a's hinzufüge.
Ich fürchte fast, es hat was mit der Wahl meines "n" zu tun, aber rein von der Logik her, kann ich für jedes n ja einfach Zerlegung finden in der v=a ist. Und das kann ich ja beliebig aufpumpen.
Die Klausur ist zwar eh gelaufen, aber vllt kann mir jemand sagen, wie man das richtig gelöst hätte 
Grüße
|
|
|
03.02.2015 18:44 |
|
|
|










